Lessons from Building Claude Code: So lernst du, wie ein Agent zu sehen
7 Min Lesezeit•Tweetvon Thariq27.2.2026•Original lesen
3 wichtigste Kernaussagen
- Der härteste Teil beim Agent-Bau ist das Design des Action Space: Nicht möglichst viele Tools, sondern die passenden Tools für das Fähigkeitsprofil des Modells.
- Features funktionieren nur, wenn das Modell sie zuverlässig und gern nutzt, wie der Weg von ExitPlan-Workarounds zum AskUserQuestion-Tool zeigt.
- Mit stärkeren Modellen müssen alte Tool-Entscheidungen regelmäßig überarbeitet werden, etwa der Wechsel von Todos zu Task-basierten Multi-Agent-Workflows.
Kurzkontext: [[Thariq]] ordnet die Entwicklung entlang von [[Claude Code]] ein.
Der Thread von Thariq ist kein "10 Tipps für bessere Agents"-Post, sondern ein echter Engineering-Rückblick aus der Entwicklung von Claude Code. Der zentrale Begriff ist der Action Space: also die Menge an Dingen, die ein Agent praktisch tun kann.
Gute Agent-Systeme entstehen nicht durch mehr Tools, sondern durch Tools, die zur tatsächlichen Denk- und Arbeitsweise des Modells passen.
Wenn du selbst Agenten baust, ist das einer der wichtigsten Punkte überhaupt. Nicht die Anzahl der Funktionen entscheidet, sondern ob das Modell diese Funktionen stabil versteht, korrekt aufruft und in realen Loops produktiv nutzt.
Das Kernproblem: Wie entwirfst du den Action Space?
Claude arbeitet über Tool Calling, aber die Tool-Form kann sehr unterschiedlich sein: Bash, Skills, Code Execution oder eigene spezialisierte Werkzeuge. Theoretisch kannst du dem Agenten ein einziges universelles Tool geben oder 50 kleine Spezialwerkzeuge.
Thariq beschreibt dafür ein gutes Denkbild: Stell dir vor, du bekommst ein schweres Matheproblem. Was hilft dir?
- Papier hilft, aber nur begrenzt.
- Ein Taschenrechner ist besser, braucht aber Bedienkompetenz.
- Ein Computer ist am stärksten, verlangt aber operative Fähigkeiten.
Diese Analogie überträgt sich 1:1 auf Agenten:
- Ein Tool ist nur dann nützlich, wenn das Modell es kompetent einsetzen kann.
- Zu viele Optionen erhöhen die Entscheidungs- und Fehlerlast.
- Zu wenige Optionen limitieren Handlungsspielraum und Effizienz.
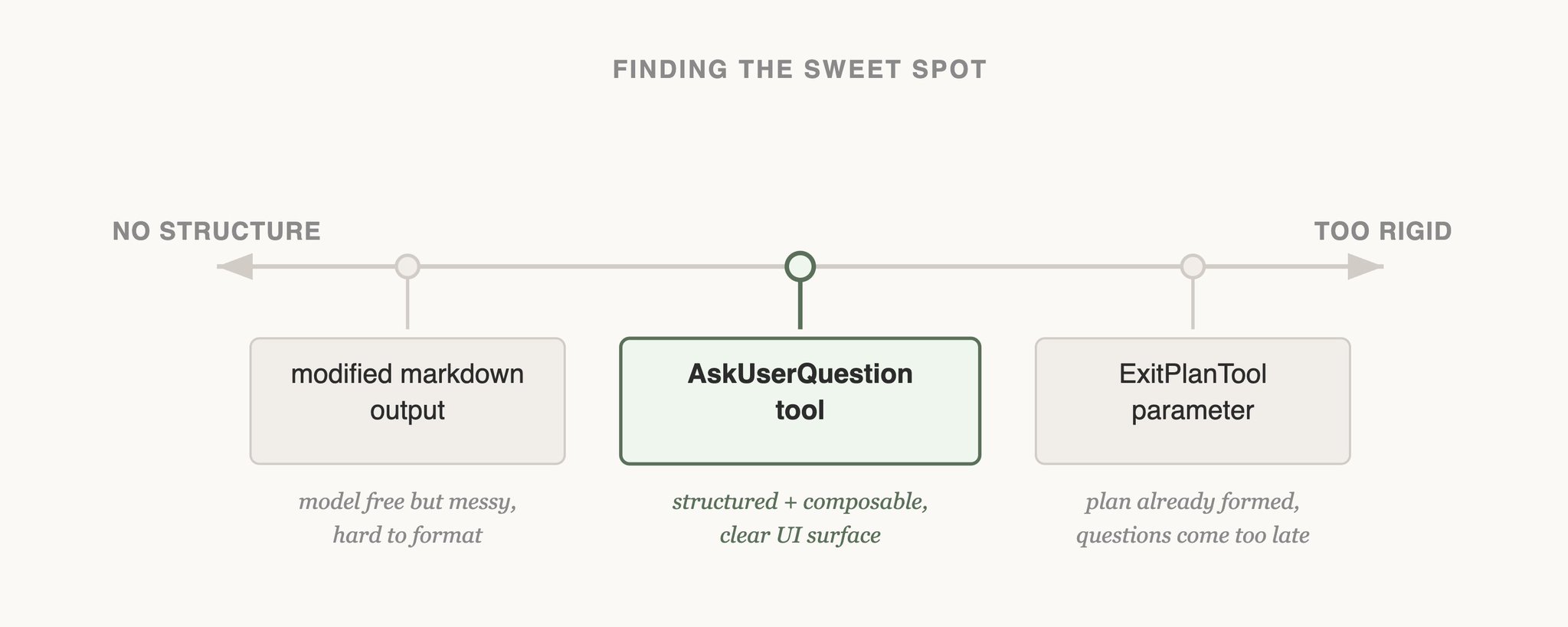
Fallstudie 1: Elicitation und das AskUserQuestion-Tool
Ein Schwerpunkt im Thread ist, wie das Team die Fragefähigkeit von Claude verbessert hat, also Elicitation. Claude konnte zwar in freiem Text Fragen stellen, aber das war im Flow für Nutzer zu langsam und zu reibungsreich.
Attempt 1: ExitPlanTool erweitern
Erste Idee: Fragen als zusätzliche Parameter in ein bestehendes ExitPlanTool packen.
Das Problem war logisch:
- Plan und Fragen wurden vermischt.
- Antworten konnten mit dem Plan kollidieren.
- Der Ablauf wurde unklar (ein Tool-Call oder mehrere?).
Technisch einfach zu implementieren, aber semantisch instabil.
Attempt 2: Output-Format anpassen
Dann versuchten sie, Claude per Prompting in ein spezielles Markdown-Frageformat zu zwingen, das UI-seitig geparst werden kann.
Das scheiterte am typischen LLM-Problem:
- Format nicht immer konsistent.
- zusätzliche Sätze, fehlende Optionen, abweichende Struktur.
Mit anderen Worten: "General Prompting" war nicht robust genug als Interface-Vertrag.
Attempt 3: eigenes AskUserQuestion-Tool
Finale Lösung: ein explizites Tool, das Claude jederzeit aufrufen kann (besonders im Plan Mode). Beim Aufruf wird ein Modal gezeigt und der Agent-Loop blockiert, bis der User antwortet.
Warum das funktionierte:
- strukturierter Output wird erzwungen.
- Nutzer bekommen klare Auswahloptionen.
- das Feature ist kompositionsfähig (Agent SDK, Skills).
- und entscheidend: Claude nutzt das Tool gern und zuverlässig.
Das beste Tool ist wertlos, wenn das Modell nicht versteht, wann und wie es es aufrufen soll.
Fallstudie 2: Capability-Drift und der Wechsel von Todos zu Tasks
Ein zweites starkes Beispiel: Beim frühen Claude Code brauchte das Modell eine explizite Todo-Liste (TodoWrite), um auf Kurs zu bleiben. Zusätzlich gab es sogar periodische System-Reminders.
Mit besseren Modellen kippten die Effekte:
- Reminders wurden eher störend.
- starre Todo-Listen wurden limitierend.
- Subagents wurden stärker, brauchten aber bessere Koordination.
Daraus entstand der Wechsel zum Task Tool:
- Tasks mit Abhängigkeiten
- Updates über Subagents hinweg
- editierbar und löschbar
Das ist ein wichtiger Architekturpunkt: Ein Tool, das 2025 notwendig war, kann 2026 ein Bottleneck sein.
Fallstudie 3: Search-Interface und eigener Kontextaufbau
Thariq beschreibt auch die Evolution beim Kontextaufbau:
- Anfangs RAG-Vector-DB: schnell und mächtig, aber Setup-lastig und fragil.
- Dann stärkerer Agent-Self-Search-Ansatz mit Grep über die Codebase.
- Mit zunehmender Modellstärke: bessere Fähigkeit, Kontext selbst zu finden und zu verschachteln.
Der Thread betont hier Progressive Disclosure:
- Agent liest erst eine relevante Datei.
- diese verweist auf weitere Dateien.
- der Agent traversiert schrittweise tiefer statt alles upfront in den Prompt zu laden.
Das reduziert Context Rot und hält die zentrale Aufgabe (Code schreiben) im Fokus.
Progressive Disclosure ohne neues Tool: Guide-Subagent
Ein interessantes Pattern im Thread: Mehr Fähigkeit ohne zusätzliches Tool.
Beispiel: Claude sollte Fragen über Claude Code selbst beantworten (MCP-Setup, Slash Commands etc.), hatte aber dafür anfangs nicht genug internes Wissen.
Anstatt alles in den System Prompt zu kippen, wurde ein spezialisierter Claude Code Guide Subagent eingeführt:
- wird bei Self-Questions aufgerufen,
- hat eigene Suchanweisungen für Docs,
- liefert fokussierte Antworten.
So wächst der Action Space funktional, ohne den globalen Tool-Space unnötig aufzublähen.
Der wichtigste Meta-Learnings-Block
Thariq schließt mit "An Art, not a Science". Das ist keine Ausrede, sondern ein realistischer Engineering-Hinweis:
- Tool-Design ist modellabhängig.
- Tool-Design ist zielabhängig.
- Tool-Design ist umgebungsabhängig.
Es gibt keine statische Regelbibliothek, die immer passt. Du musst laufend Outputs lesen, Hypothesen testen, Werkzeuge nachschärfen und alte Entscheidungen aktiv hinterfragen.
Was du direkt in deiner Agent-Architektur anwenden kannst
Wenn du eigene Agenten baust, lassen sich aus dem Thread fünf konkrete Regeln ableiten:
-
Tools nur bei klarer Verhaltenslücke hinzufügen
Nicht "Feature parity", sondern diagnostizierte Failure Modes beheben. -
Interfaces robust machen, nicht nur prompten
Wenn Format-Treue kritisch ist, nutze Tool-Verträge statt freies Markdown. -
Tool-Nutzung messen, nicht nur Tool-Verfügbarkeit
Instrumentiere, ob das Modell ein Tool korrekt und freiwillig nutzt. -
Capability-Reviews als Routine etablieren
Alte Hilfskonstrukte (Reminders, starre Todos) können bei stärkeren Modellen regressiv wirken. -
Progressive Disclosure als Standard für Kontext
Kontext iterativ laden lassen statt alles upfront in den Prompt zu packen.
Fazit
Der Thread ist ein ungewöhnlich ehrlicher Blick auf Agent-Produktentwicklung in der Praxis. Die große Botschaft lautet nicht "mehr Agent-Magie", sondern "besseres Interface-Design zwischen Modell, Tools und Nutzer".
Wenn du das auf einen Satz verdichtest:
Lerne, wie dein Modell wirklich arbeitet, und forme seinen Action Space so, dass es darin natürlich und zuverlässig handeln kann.
Genau darin steckt der Unterschied zwischen einer Demo und einem System, das im Alltag wirklich trägt.
Verbindungen
- [[Thariq]]
- [[Claude Code]]
- [[Action Space]]
- [[Tool Design]]
- [[Agenten-UX]]
- [[Task-Based Workflows]]